Hàm mục tiêu (objective function)
Giữa training và evaluation, evaluation đơn giản hơn vì bạn chỉ việc đưa observation vào model, nhận về label dự đoán, và tính giá trị của evaluation function trên test set. Training phức tạp hơn vì quá trình này phải đảm bảo rằng model phải có khả năng dự đoán tốt không chỉ trên training set mà còn trên test set (là dữ liệu không được model nhìn thấy lúc train). Bài viết giải thích tại sao không thể sử dụng các evaluation function như error rate để train model, và giới thiệu về khái niệm hàm mục tiêu (objective function).
Mục tiêu tối thượng của supervised learning
Khi nói đến việc "giải" training problem tức là ta đang nói đến việc tìm một phương pháp huấn luyện trên training set sao cho model dự đoán tốt trên test set. Người ta thường ít quan tâm đến độ tốt của model trên training set bởi vì nó thường rất cao (nhất là với các model cực mạnh của deep learning). Độ tốt trên training set chỉ thể hiện được khả năng ghi nhớ của model về những gì đã nhìn thấy. Với một trí thông minh thật sự, ta cần thêm khả năng tổng quát hóa, chính là việc dự đoán tốt trên dữ liệu chưa hề được nhìn thấy.
Objective function
Để dự đoán tốt nhất trên test set, cách đơn giản nhất là tìm model dự đoán tốt nhất trên training set, và hy vọng rằng nó cũng sẽ dự đoán tốt trên test set. Vì thế, ở bài trước ta phát biểu rằng: 1. Train: tìm model tối thiểu hóa giá trị của evaluation function trên training set. 2. Test: thông báo độ tốt của là gía trị của evaluation trên test set.
Tuy nhiên, cách làm này trong thực tế vừa rất khó thực hiện được vừa không hiệu quả. Ta chỉ tìm ra hai vấn đề trong phát biểu trên và thay đổi để làm nó thực tế và hiệu quả hơn.
Thứ nhất, khi train model ta chỉ muốn tìm ra model dự đoán "khá" chính xác trên training set mà thôi. Vì sao là "khá" chính xác mà không phải là "hoàn toàn" chính xác?
Không có điều gì đảm bảo model dự đoán hoàn chính xác trên train set cũng dự đoán tốt trên test set cả. Thậm chí nó có thể dự đoán rất tệ nếu test set rất khác với train set. Điều giống như việc bạn bị "trật tủ" khi đi vậy (ôn một đằng đề ra một kiểu). Thường trong các bài toán, bạn có một khối dữ liệu lớn từ một nguồn nào đó rồi chia ra 80% để train và 20% để test. Vì thế mà training set và test set sẽ có cùng một nguồn (nói chính xác hơn là cùng một phân bố xác suất). Ví dụ nhưng training set của bạn là ảnh có nhiều cây cối, thì trong test set cũng sẽ có nhiều cây cối. Nhưng mà dù có gần giống nhau như vậy, hai set này cũng vẫn có những khác biệt nhất định. Ta phải đánh đổi giữa khả năng ghi nhớ và khả năng tổng quát hóa của model. Model muốn ghi nhớ càng tốt thì lại càng phải xử lý nhiều trường hợp ngoại lệ. Có khi, một observation được gán label theo một logic rất kì lạ và hiếm gặp. Lúc này, model phải đặt ra ngoại lệ. Việc đặt ra quá nhiều ngoại lệ làm model bớt tính tổng quát, vì ngoại lệ là những quy luật mà chỉ đúng với một số ít trường hợp. Để hạn chế những ngoại lệ này, ta chỉ cần model đoán "khá" chính xác trên train set mà thôi. Bù lại model sẽ tổng quát hơn và đoán chính xác hơn trên test set. Suy cho cùng, độ tốt trên test set mới là thứ ta quan tâm sau cùng.
Thứ hai, trong phát biểu trên ta dùng cùng một loss function cho cả train và test. Đây là một trường hợp rất lý tưởng và hiếm gặp trong thực tiễn. Trong đa số trường hợp, loss function được sử dụng lúc train và lúc test không giống nhau. Kì lạ đúng không? Tại sao chúng ta "dạy" một đằng, nhưng mà lại "ra đề" một nẻo?
Evaluation function thường dùng thường rất khó để tối thiểu hóa bằng các phương pháp toán học (sẽ giải thích ngay sau phần này). Lý do khái quát là do các evaluation function này thường là tổng của của các loss function có dạng 0-1 loss, tức là chỉ trả về 0 hoặc 1 và phải trùng hoàn toàn với label thật thì mới nhận được 0. Error rate là một ví dụ điển hình của 0-1 loss. Đối với những hàm như vậy, nếu model đoán sai thì không biết sửa chữa theo hướng nào để tiến bộ hơn.
Khi train, ta cần một loss function cho partial credit, tức là đúng tới đâu cho điểm tới đó và dự đoán thế nào cũng có điểm. Model có thể tận dụng điều này để thay đổi câu trả lời một chút xem điểm tăng hay giảm, dần dần tìm ra câu trả lời đúng. Một trong những loss function thường được sử dụng nhất là negative log-likelihood. Khi sử dụng loss function này, model của chúng ta thay vì đưa ra một đáp án cụ thể, thì sẽ đưa ra xác suất observation mang label , tức là . Negative log-likelihood được định nghĩa như sau:
Ta thấy là nếu model đưa xác suất 100% cho label thật y, thì loss function sẽ có giá trị và model không bị phạt. Hơn nữa, cho dù model đưa ra xác suất thế nào thì cũng đều nhận được loss tương ứng với độ sai. Ví dụ, ta dự đoán thì độ sai là
Ta gọi hàm được model tối ưu lúc train là objective function để phân biệt với evaluation function lúc test. Objective function thường có dạng như sau:
Giống như evaluation function, objective function cũng gồm giá trị trung bình của loss function (lưu ý, loss function này khác với loss function của evaluation function). Objective function còn có thêm regularizer. Tác dụng của regularizer chính là để giải quyết vấn đề đầu tiên ta nhắc đến, làm cho model chỉ dự đoán "khá" chính xác training set mà thôi.
Giống với evaluation function, nếu không có regularizer, objective function cũng đảm bảo tính chất tối ưu: model nhận được giá trị 0 khi và chỉ khi dự đoán hoàn hảo training set. Vì thế, ta cần thêm regularizer vào objective function để điều này không xảy ra. Bài viết sau sẽ nói rõ hơn về điều này.
Câu hỏi: evaluation function và objective function khác nhau thế nào?
Trả lời: khác nhau ở dạng của loss function và regularizer.
Đến đây ta phát biểu lại về hai quá trình của supervised learning: 1. Train: tìm tối thiểu hóa objective function . 2. Test: đo độ tốt của bằng evaluation function .
Đọc thêm: vì sao không dùng error rate để train model?
Như ta đã biết, quá trình train model về bản chất là tối ưu một hàm số. Từ kiến thức đã học từ cấp 3, ta cũng biết rằng việc tối ưu hàm số có liên quan đến đạo hàm (ví dụ như đạo hàm ở điểm cực tiểu của một hàm số bằng 0). Cụ thể hơn, trong supervised learning, ta thường tối ưu hàm số bằng gradient descent, tức là dùng gradient (đạo hàm nhiều biến) để dẫn lối cho ta đi đến điểm cực tiểu. Phương pháp này sẽ được giới thiệu chi tiết trong một bài khác. Để dễ hiểu, bạn có thể hình dung tối ưu hàm số như là đi tìm thung lũng thấp nhất trong một vùng núi non. Cách đơn giản nhất là bạn cứ thả mình lăn xuống dốc cho đến khi nào dừng lại. Gradient giống nhưng tổng lực của lực hấp dẫn và phản lực của mặt đất, sẽ kéo bạn lăn về nơi thấp hơn cho đến khi mặt đất không còn dốc nữa.
Khi nhìn lại một evaluation function như là error rate:
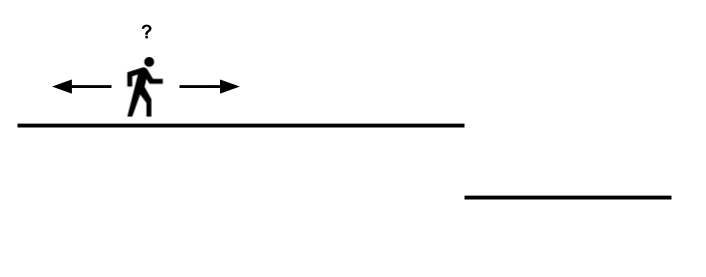
ta thấy không có gradient liên tục. Ta có thể tưởng tượng việc không có gradient liên tục giống như hàm số bị "gãy" ở một số điểm nào đó. Trong trường hợp này, khi ta cho đi từ đến , hàm hầu hết mang giá trị 1 và gradient bằng 0. Chỉ đến điểm mà , hàm này độ nhiên giảm xuống giá trị 0 và gradient ở đây không được định nghĩa. Hơn nữa, ở những điểm mà hàm này có gradient, thì gradient lại vô dụng (bằng 0). Hình vẽ này sẽ giúp bạn dễ hình dung hơn,
Ở đây model của chúng ta đang được giả định là chỉ có 1 parameter (ví dụ như với parameter là ). Đường ngang thể hiện cho đồ thị với trục ngang là tham số, trục dọc là giá trị error rate ứng với tham số. Việc đi sang trái/phải thể hiện cho việc tăng/giảm tham số. Gỉa sử model đang lạc ở vùng mà error rate đang có giá trị là 1. Xung quanh gần đó hoàn toàn là một vùng bằng phẳng (gradient bằng 0). Model hoàn toàn không biết nên đi về hướng nào (tăng hay giảm parameter) để đến được vùng thấp hơn. Model không thể nhìn qúa xa và không thể nào biết được là đi thêm về bên phải một đoạn sẽ đạt được error rate tối ưu (bằng 0). Trong thực tế, model có rất nhiều parameter và, với mỗi parameter, ta phải ra quyết định tăng hay giảm như thế này.
Last updated