Regularized Loss Minimization
Chúng ta sẽ hoàn tất những hiểu biết về overfitting và đưa ra một thuật toán supervised learning hiệu quả hơn ERM để chống lại overfitting. Nhưng trước khi đó ta cùng ôn lại những gì đã học ở phần trước bằng một số câu hỏi ngắn như sau:
Q1 : Overfitting là gì?
A1 : Là khi model không có khả năng tổng quát từ những gì đã học được: độ sai sót trên training set nhỏ, trên test set to.
Q2 : Tại sao overfitting lại có hại?
A2 : Vì dữ liệu lúc nào cũng chứa noise. Noise làm cho model tìm được phức tạp quá mức cần thiết.
Q3 : Làm sao để biết được model có bị overfitting hay không?
A3 : Theo dõi learning curve.
Q4 : Làm sao để không bị overfitting?
Nguyên nhân gây ra overfitting
Như chúng ta đã biết, noise không phải là nguyên nhân trực tiếp gây ra overfitting. Vậy những yếu tố nào gây ra overfitting? Overfitting là sản phẩm của sự cộng hưởng giữa các yếu tố sau:
Sử dụng ERM làm objective function. vì objective function và evaluation function có thể rất khác nhau, tối ưu objective function chưa hẳn sẽ tối ưu evaluation function.
Vì sao dùng model quá mạnh lại không tốt?
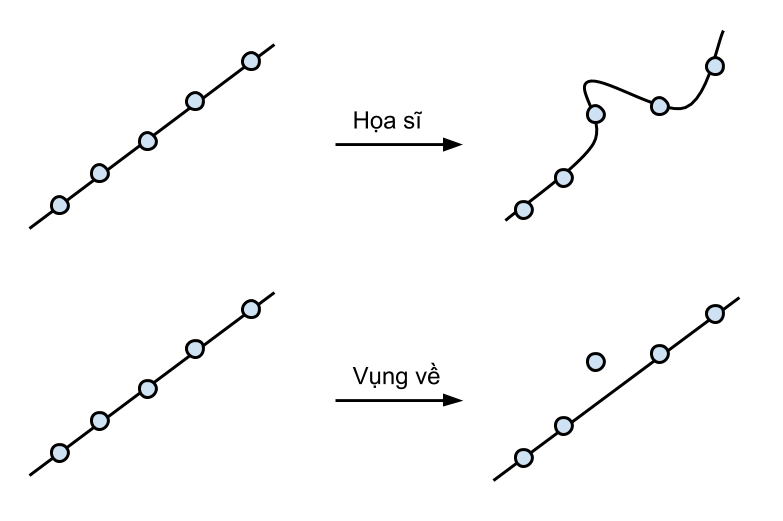
Giả sử có một cuộc thi trong đó ta yêu cầu mỗi thí sinh phải vẽ được một đường đi qua nhiều nhất các điểm cho trước. Thí sinh tham dự có 2 người: một người là họa sĩ, anh ta rất khéo tay và có thể vẽ tất cả các loại đường cong thẳng; người còn lại là một anh chàng vụng về với cây thước kẻ, anh ta chỉ có thể vẽ đường thẳng. Dĩ nhiên là anh họa sĩ sẽ thắng trong trò chơi này.
Nhưng hãy xem xét phản xạ của hai thí sinh trong tình huống sau đây: ta cho đề bài ban đầu là các điểm trên một đường thẳng; sau khi hai người vẽ xong, ta chỉ dịch chuyển một điểm lệch ra khỏi đường thẳng một đoạn nhỏ. Hiển nhiên là ban đầu cả hai người đều vẽ được một đường thẳng đi qua tất cả các điểm. Nhưng sau khi một điểm bị dịch chuyển, anh họa sĩ sẽ vẽ ra một đường hoàn toàn khác với đường thẳng ban đầu để cố đi qua mọi điểm. Ngược lại, anh vụng về thì sẽ vẫn giữ nguyên đáp áp vì đó là đáp án tốt nhất anh có thể vẽ. Điều ta thấy được ở đây đó là anh họa sĩ, vì quá tài hoa, nên anh rất nhạy cảm với những thay đổi nhỏ trong các điểm dữ liệu. Còn anh vụng về, vì năng lực của anh có hạn, nên thường anh sẽ ít bị ảnh hưởng hơn.
Nếu như đây không phải là một cuộc thi vẽ qua nhiều điểm mà là một bài toán machine learning, có lẽ anh họa sĩ đã thua rồi. Bởi vì điểm bị dịch chuyển có thể là do tác động của noise để hòng đánh lừa anh. Anh họa sĩ đại diện cho một tập model cực mạnh, có khả năng mô phỏng mọi hàm số. Một tập model mạnh như vậy rất nhạy cảm với noise và dễ dàng bị overfitting.
Sự kết hợp giữa các yếu tố gây overfitting
Các yếu tố gây ra overfitting phải phối hợp với nhau thì mới đủ điều kiện cho nó xuất hiện. Ta xem xét hai tình huống thường gặp sau:
Có nhiều dữ liệu: ta có thể vô tư dùng ERM, tập model mạnh mà không lo về overfitting. Đây chính là lý do mà thế giới hân hoan khi Big Data xuất hiện.
Làm việc với model yếu: các model thường bị một hội chứng chị em ngược lại với overfitting, gọi là underfitting. Đây là khi model quá đơn giản so với quan hệ cần tìm. Lúc này, dù có tăng thêm dữ liệu cũng không giúp cho model chính xác thêm. Điều cần làm đó là tăng sức mạnh (tăng số lượng tham số hoặc thay đổi dạng) của model.
Mình cũng xin dành ra vài dòng để nói về hiện tượng "cuồng" deep learning và áp dụng deep learning lên mọi bài toán. Các model của deep learning là các neural network cực mạnh nên cần rất nhiều dữ liệu để không bị overfitting. Đó là lý do mà dù các model deep learning này không mới, thậm chí là những model đầu tiên của machine learning, nhưng phải chờ đến kỷ nguyên Big Data hiện tại chúng mới phát huy sức mạnh. Nếu không am hiểu về overfitting và áp dụng deep learning vô tội vạ lên những tập dữ liệu chỉ có vài trăm cặp dữ liệu thì thường đạt đượt kết quả không cao. Khi gặp những điều kiện dữ liệu eo hẹp như vậy, nên bắt đầu từ những model đơn giản như linear model trước. Trong machine learning có một định lý nổi tiếng gọi là "no free lunch" nói rằng không có một model nào tốt nhất cho tất cả các loại dữ liệu. Vì thế, tùy vào bài toán, vào tính chất và số lượng dữ liệu sẵn có, ta mới xác định được model phù hợp.
Regularized loss minimization
Trong bài trước, ta đã biết được một phương pháp để giảm thiểu overfitting, early stopping. Ba yếu tố gây ra overfitting cũng gợi ý cho chúng ta những cách khác để khắc phục vấn đề này. Trong đó, yếu tố thứ hai đưa ra giải pháp đơn giản nhất: tăng kích thước tập huấn luyện. Sau đây, mình sẽ giới thiệu một phương pháp nhằm loại trừ đi yếu tố thứ nhất và thứ ba, được gọi là regularization. Phổ biến nhất, phương pháp này sẽ thêm vào ERM objective function một regularizer nhằm hạn chế sức mạnh của model.
Các regularizer thường gặp
tức là tổng của trị tuyệt đối của các thành phần. 1-norm đặc biệt ở chỗ là, khi đưa vào hàm mục tiêu, nó sẽ thường cho ra model thưa, tức là model có parameter chứa nhiều chiều bằng 0. Model thưa rất có lợi thế trong tính toán và lưu trữ vì ta chỉ cần làm việc trên các chiều khác 0.
Last updated